Instalamos los paquetes necesarios desde repositorios
sudo apt get install tesseract-ocr-spa gscan2pdf
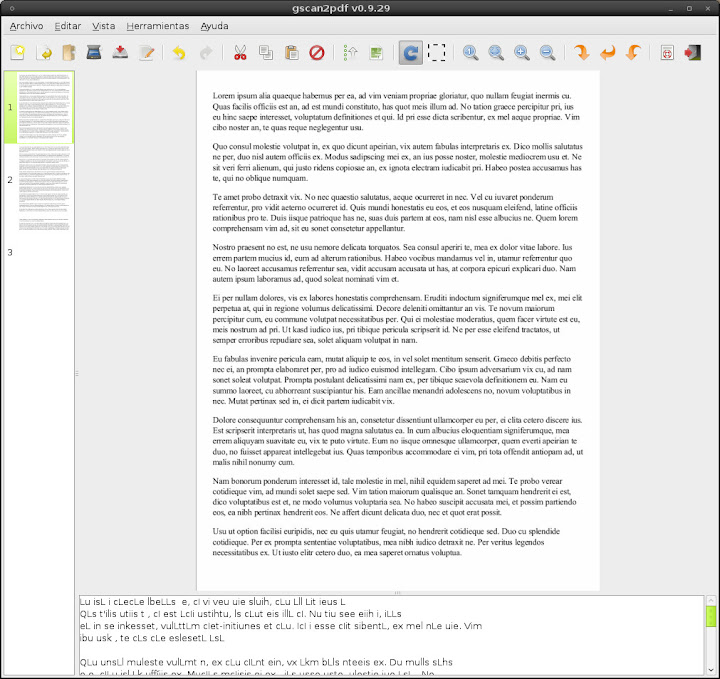
Aplicaciones >> Gráficos >> gscan2pdf y veremos lo siguiente:
importamos las imágenes para pasar el OCR
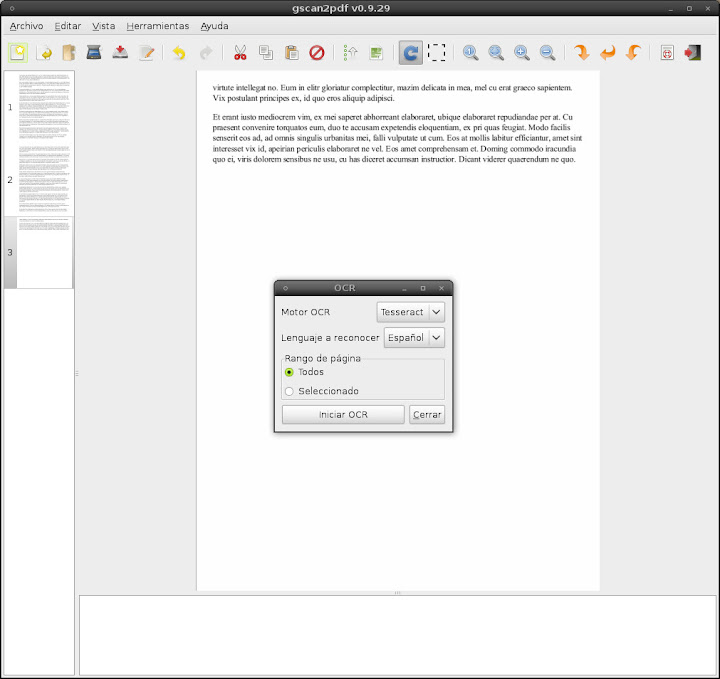
En Herramientas seleccionamos OCR y en la ventana que se despliega escogemos el motor OCR que vamos a usar:
Al pie vemos los caracteres identificados por el OCR. Los resultados no son los mejores pero es lo que tenemos de momento disponible.